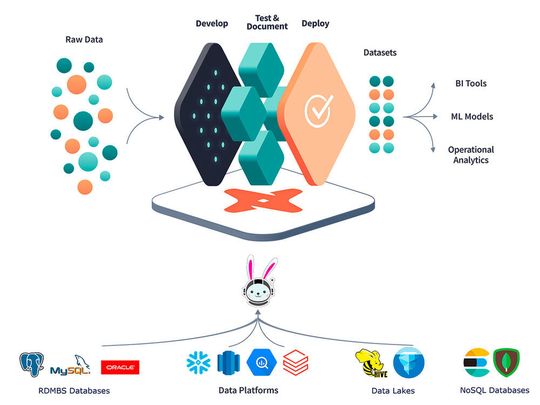
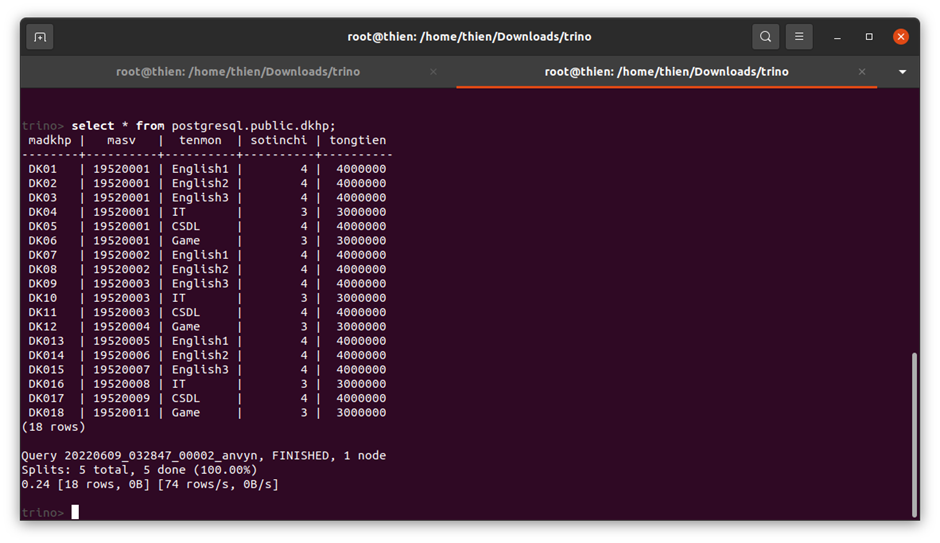
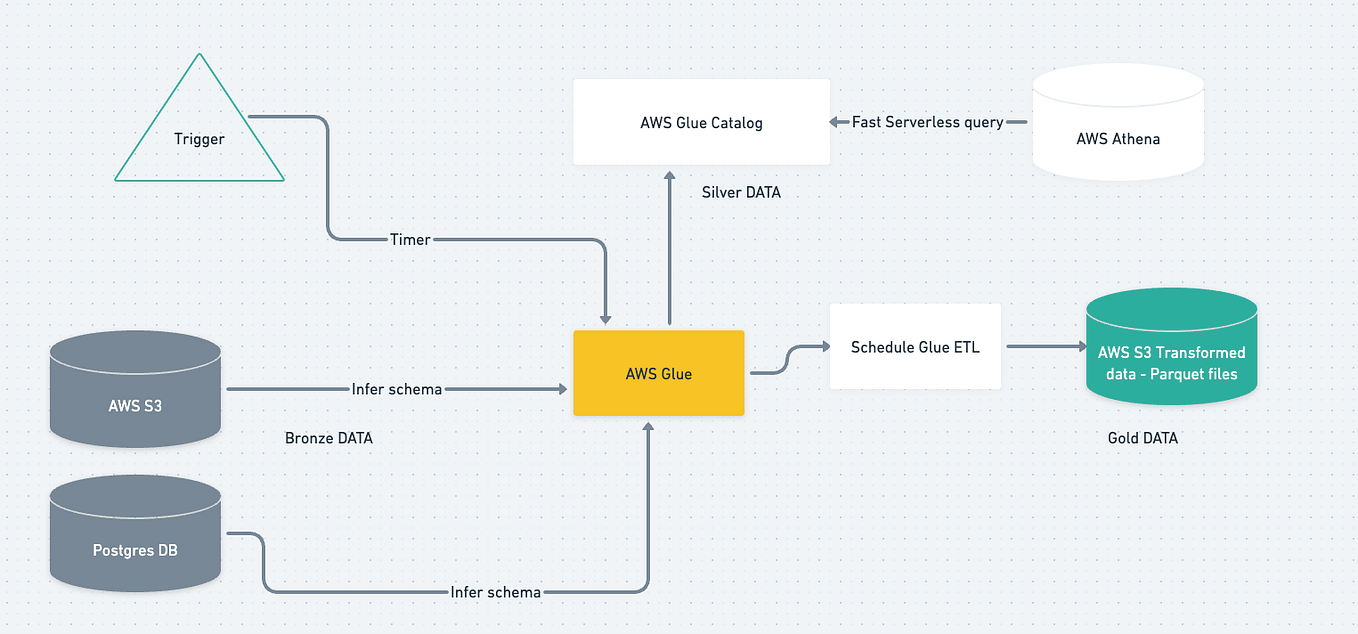
Trino est un moteur de requête SQL distribué open source conçu pour interroger de grands ensembles de données répartis sur une ou plusieurs sources de données hétérogènes. Trino peut interroger des lacs de données qui contiennent des formats de fichiers de données ouverts orientés colonnes comme ORC ou Parquet,, résidant sur différents systèmes de stockage comme HDFS, AWS S3, Google Cloud Storage ou Azure Blob Storage en utilisant les formats de table Hive, Delta Lake et Iceberg. Trino a également la capacité d'exécuter des requêtes fédérées qui interrogent des tables dans différentes sources de données telles que MySQL, PostgreSQL, Cassandra, Kafka, MongoDB et Elasticsearch Trino est publié sous la licence Apache.
Histoire
En , les créateurs originaux de Presto, Martin Traverso, Dain Sundstrom et David Phillips, ont créé un fork du projet Presto. Ils ont initialement conservé le nom Presto et ont utilisé PrestoSQL comme nom de projet pour le distinguer du projet PrestoDB d'origine. Simultanément, ils ont annoncé la création de la Presto Software Foundation. La fondation est une organisation à but non lucratif vouée à la promotion du moteur de requête SQL distribué open source Presto,.
En , PrestoSQL a été rebaptisé Trino. La Trino Software Foundation, le code source et d'autres éléments de PrestoSQL ont été renommés à la suite du changement de nom du projet.
Presto et Trino ont été initialement conçus et développés par Martin, Dain, David et Eric Hwang de Facebook pour permettre aux analystes de données d'exécuter des requêtes interactives sur leur grand entrepôt de données dans Apache Hadoop. Trino partage les six premières années de développement avec le projet Presto, Pour en savoir plus sur l'histoire antérieure de Trino, vous pouvez consulter la section Historique de Presto.
Architecture
Trino est écrit en Java. Il contient deux types de nœuds, le coordinateur et le worker.
- Le coordinateur est responsable du parsing, de l'analyse, de l'optimisation, de la planification et de l'orchestration d'une requête soumise par un client. Le coordinateur interagit avec l'interface du fournisseur de services (SPI) pour obtenir les tables disponibles, les statistiques des tables et d'autres informations nécessaires à l'exécution de ses tâches.
- Les workers sont responsables de l'exécution des tâches et des opérateurs qui leur sont fournis par le planificateur. Ces tâches traitent les lignes des données sources et produisent les résultats qui sont renvoyés au coordinateur et finalement renvoyés au client.
Trino adhère à la norme ANSI SQL et inclut diverses parties des spécifications ANSI suivantes : SQL-92, SQL:1999, SQL:2003, SQL:2008, SQL:2011, SQL:2016.
Trino propose une architecture qui sépare le calcul et le stockage et peut être déployé à la fois sur site et dans le cloud.
Trino a une architecture MPP de calcul distribué. Trino répartit d'abord le travail sur plusieurs workers en exécutant des opérations de partitionnement ad hoc ou en s'appuyant sur des partitions existantes dans les données du stockage sous-jacent. Une fois que ces données sont dans le worker, les données sont traitées via des opérateurs en pipeline exécutés sur plusieurs threads.
Notes et références
Voir aussi
Articles connexes
- Presto (moteur de requête SQL)
- Big data
- Apache Drill
- Grappe d'ordinateurs
Liens externes
- (en) Trino Software Foundation (anciennement Presto Software Foundation)
- Portail du logiciel
- Portail des données